
AI“玩”手机,有哪些坑?一文读懂→
2025-05-06 10:00:07 阅览:416
【导语】自去年以来,智能体(agent)技术迎来了前所未有的大爆发,特别是在手机端展现出巨大的应用潜力。以大语言模型(LLM)为核心,结合多种关键组件,手机agent正逐步实现在各行各业中的落地应用。浙江大学、vivo与香港中文大学的研究团队在预印本网站arXiv上发表的综述论文,深入探讨了手机GUI agent的发展现状、挑战及未来方向。从自动化进程到LLM的集成,再到多模态感知与行动执行,手机agent正逐步迈向更加智能、高效与个性化的未来。然而,数据集开发、设备上部署、用户适应性、模型能力提升、评估基准标准化及安全可靠性等方面仍面临诸多挑战。业内需共同努力,推动手机agent技术的不断进步,为用户带来无缝、安全且个性化的智能体验。
自去年以来,智能体(agent)迎来了大爆发。以大语言模型(LLM)为大脑,配合其他关键组件,集自主性、响应性、主动性和社交能力于一体的 agent,有望在各行各业实现更多落地应用。
尤其是在手机端,作为人们日常生活和工作不可或缺的大众工具,手机一旦具备了 AI agent 能力,其应用场景充满想象力。
那么,如今的手机 agent 已经可以帮我们做什么?又有哪些问题亟待解决?未来的手机 agent 形态会是怎样的?
最近,来自浙(zhè)江(jiāng)大(dà)学(xué)、vivo 和香港中文大学的研究团队合作在预印本网站 arXiv 上发表了一篇关于手机 GUI agent 的综述,详细解答了上述问题。

论文链接:https://arxiv.org/abs/2504.19838
研究团队从手机自动化的发展、手机 GUI agent 的框架和组成部分、手机自动化的LLM、挑战和(hé)未(wèi)来(lái)方(fāng)向等几个方面,详细介绍了基于 LLM 的 agent 如何应用于手机自动化。
他们在论文中写道,基(jī)于(yú) LLM 的(de) agent 创(chuàng)造了一种新的模式,使移动界面操作更加智能,通过整合自然语言处理、多模态感知和行动执行能力,来理解、规划和执行移动设备上的任务。这些 agent 可以识别界面、理解指令、实时感知变化并做出动态响应。
手机自动化的发展
LLM 的出现标志着手机自动化领域发生了重大转变,它使人们能够与移动设备进行更加动态、上下文感知和复杂的交互。在有关 LLM 驱动的手机 GUI agent 的里程碑中,模型越(yuè)来(lái)越善于解释多模态数据、推理用户意图并自主执行复杂任务。
基于 LLM 的手机自动化存在 scaling law,随着数据集的扩大,包含的应用程序、使用场景和用户行为也越来越多样化,在诸如点击按钮或输入文本(běn)等分步自动化任务方面它取得了持续的进步。这种数据扩展不仅能捕捉到更广泛的界面布局和设备上下文,还能揭示潜在的“涌(yǒng)现(xiàn)”能(néng)力(lì),使(shǐ) LLM 能(néng)够(gòu)处(chù)理(lǐ)更(gèng)抽(chōu)象(xiàng)的多步骤指令。
来自域内场景的经验证据进一步证明,扩大手机应用和用户模式的覆盖范围可以系统地提高自动化的(de)准(zhǔn)确(què)性。从本质上讲,随着模型规模和数据复杂性的增长,手机 GUI agent 利用这些 scaling law,在用户意图和现实世界 GUI 交互之间架起了桥梁,效率和复杂性也在不断提高。
LLM 通过从大量文本语料库中学习,改变了手机自动化的自然语言处理。这种训练可以捕捉到复杂的语言结构和领域知识,使 agent 可以使用多步骤命令并生成基于上下文的响应。手机 GUI agent 得益于强大的自然语言基础,弥补了基于脚本的系统中曾经普遍存在的用户意图差距。
GUI 屏幕具有多模态感知功能。UGround、Ferret-UI 和 UI-Hawkexcel 等系统将自然语言描述与屏幕元素相结合,并随着界面的发展进行动态调整。此外,SeeClick 和 ScreenAI 证明,直接从屏幕截图而不是纯文本元数据中学习,可以进一步增强适应性。通过将视觉感知与用户语言相结合,基于 LLM 的 agent 可以更加灵活地应对各种用户界面设计和交互场景。
通过将语言、视觉上下文和历史用户交互结合起来,LLM 还能进行高级推理和决策。通过在广泛的语料库中进行预训练,这些模型就具备了进行复杂推理、多步骤规划和上下文感知适应的能力。
LLM 的集成使新颖的商业应用成为可能,苹果的 Apple **Intelligence、**智谱的 AutoGLM、Anthropic 的 Computer Use、荣耀的 YOYO Agent 和 vivo 的 PhoneGPT等应用,利用手机自动化实现了更加自然、高效和个性化的人机交互,为现实世界的挑战提供了创新解决方案。
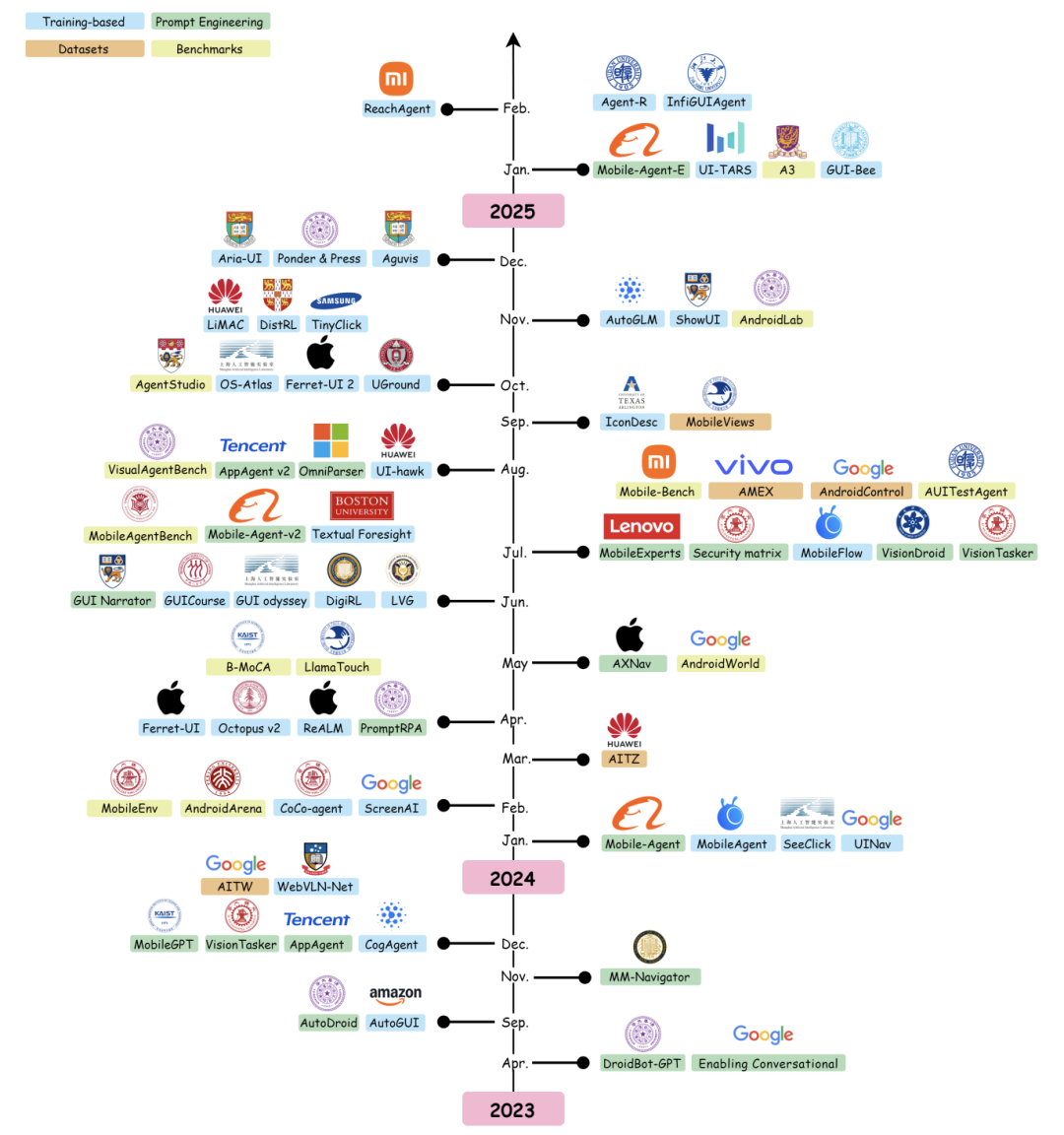
图|由 LLM 驱动的手机 GUI agent 里程碑。
手机 GUI agent 框架和组成
由多模态大语言模型(MLLM)驱动的手机 GUI agent 可以使用不同的架构范例和组件进行设计,包括简单的单 agent 系统以及更复杂的多 agent 或多阶段方法等。
最基本的方案是单个 agent 逐步运行,而不从一开始就预先计算整个动作序列。相反,该 agent 会持续观(guān)察(chá)动(dòng)态(tài)变(biàn)化(huà)的(de)移(yí)动(dòng)环(huán)境(jìng),其(qí)中(zhōng)可(kě)用(yòng)的用户界面元素、设备状态和相关的上下文因素可能会以不可预测的方式发生变化,因此无法事先进行详尽的计算。因此,agent 必须逐步调整自己的策略,根据当前情况做出决策,而不是遵循固定的计划。这种迭代决策过程可以使用部分可观测马尔可夫决策过程(POMDP)进行有效建模,POMDP 是处理不确定性条件下连续决策的成熟框架。通过将任务建模为 POMDP,我们可以捕捉到任务的动态性质、预先计划所有行动的不可能性以及在每个决策点调整 agent 方法的必要性。
感知是 MLLM 驱动的手机 GUI agent 基本框架的一个基本组件。它负责捕捉和解释移动环境的状态,使 agent 能够理解当前环境并做出明智的决策。在整个流程中,感知是 POMDP 的初始步骤,为推理和行动模块的有效运行提供必要的输入。
基于 LLM 的手机自动化 agent 的大脑是其认知核心,主要由 LLM 构成。LLM 是 agent 的推理和决策中心,使其能够在移动环境中解释输入、生成适当的响应并执行操作。利用 LLM 中蕴含的大量知识,agent 可以从高级语言理解、上下文感知以及在不同任务和场景中的泛化能力中获益。
行动组件是由 MLLM 驱动的手机 GUI agent 的重要组成部分,负责执行大脑在移动环境中做出的决策。通过将 LLM 生成的高级命令与低级设备操作连接起来,agent 可以有效地与手机的用户界面和系统功能进行交互。操作包括各种各样的操作,从点击按钮这样的简单交互,到启动应用程序或修改设备设置这样的复杂任务,等等。执行机制利用 Android 的 UI Automator、iOS 的 XCTest 或 Appium 和 Selenium 等流行的自动化框架等工具,向手机发送精确的命令。通过这些机制,agent 可确保将决策转化为设备上切实可靠的操作。
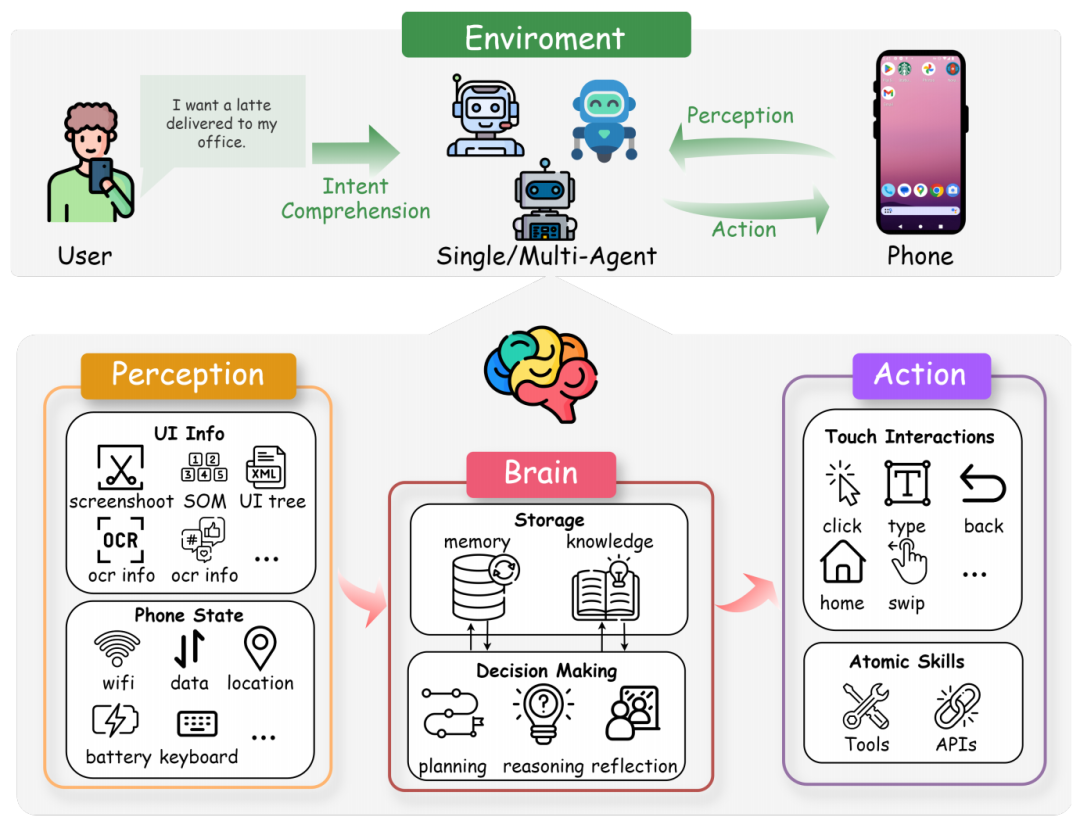
图|由 MLLM 驱动的手机 GUIagent 框架概述。
虽然基于 LLM 的单 agent 框架在屏幕理解和推理方面取得了重大进展,但它们是作为孤立的实体运行的。这种孤立性限制了它们在复杂任务中的灵活性和可(kě)扩(kuò)展(zhǎn)性(xìng),因(yīn)为(wèi)复杂任务可能需要多种协调技能和适应能力。对于需要根据实时反馈、多阶段决策或不同领域的专业知识进行持续调整的任务,单 agent 系统可能难以胜任。此外,它们缺乏利用共享知识或与其他 agent 协作的能力,从而降低了在动态环境中的有效性。
多 agent 框架通过促进多 agent 之间的协作来解决这些局限性,每个 agent 都具有专门的功能或专业知识。这种协作方式提高了任务效率、适应性和可扩展性,因为 agent 可以并行执行任务,或根据各自的特定能力协调行动。手机自动化中的多 agent 框架可分为两种主要类型:角色协调多 agent 框架和基于场景的(de)任(rèn)务(wu)执(zhí)行(xíng)框(kuāng)架(jià)。这(zhè)些(xiē)框架通过根据一般功能角色组织 agent 或根据特定任务场景动态组装专用 agent ,为手机自动化提供了更加灵活、高效和鲁棒的解决方案。
虽然单 agent 和多 agent 框架增强了适应性和可扩展性,但有些任务仍可从明确分离高层规划和低层执行中获益。这就是“计划-执行”框架,在这一范式中,agent 首先制定概念计划,通常以人类可读指令的形式表达,然后在设备的用(yòng)户(hù)界(jiè)面(miàn)上(shàng)执(zhí)行(xíng)这(zhè)些(xiē)指(zhǐ)令(lìng)。
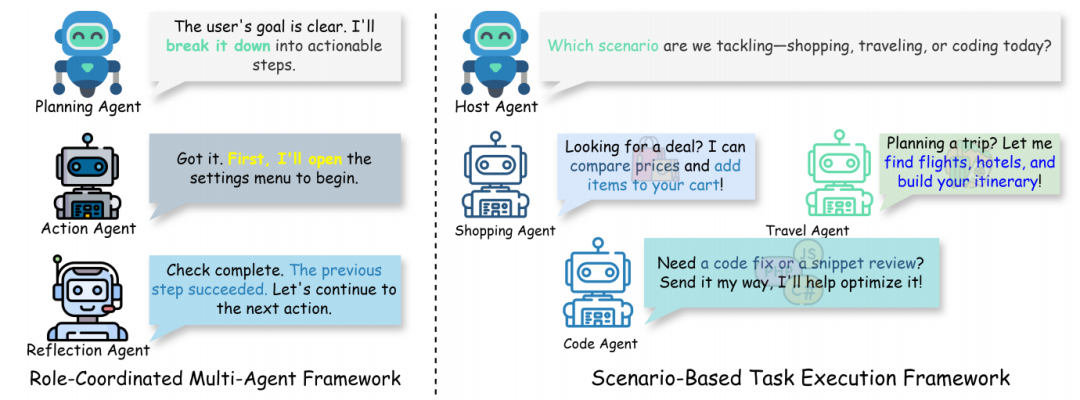
图(tú)|角(jiǎo)色(sè)协(xié)调(diào)和(hé)基(jī)于(yú)情(qíng)景(jǐng)的(de)多(duō) agent 框(kuāng)架(jià)比(bǐ)较(jiào)。
挑(tiāo)战(zhàn)和(hé)未(wèi)来(lái)方(fāng)向(xiàng)
将 LLM 集成到手机自动化中推动了重大进步,但也带来了许多挑战,要充分释放智能手机 GUI agent 的潜力,还克服以下挑战至关重要。
**数据集开发和可扩展性微调。**LLM 在手机自动化中的性能在很大程度上取决于能够捕捉真实世界中各种场景的数据集。现有的数据集往往缺乏全面覆盖所需的广度。
未来的工作重点应该是开发大规模、有注释的数据集,涵盖更广泛的应用、用户行为、语言和设备类型。纳入多模态输入(如屏幕截图、用户界面树和自然语言指令)可以帮助模型更好地理解复杂的用户界面。视频数据集有望发展成为未来 GUI 数据集的一种新形式。如何进行扩展微调以实现鲁棒的域外性能仍然是一个挑战。未来的发展方向应该是探索混合训练方法、无监督学习、迁移学习和辅助任务,以提高泛化能力,而不需要过于庞大的数据集。
**轻量级、高效的设备上部署。**在移动设备上部署 LLM 会面临大量计算和内存限制。当前的硬件往往难以支持大型模型,同时将延迟和功耗降至最低。
模型剪枝、量化和高效 transformer 架构等方法可以解决这些限制。专用硬件加速器和边缘计算解决方案可以进一步降低对云的依赖性,增强隐私保护,提高响应速度。考虑利用小语言模型(SLM)的代码生成能力,将 GUI 任务自动化转化为代码生成问题。这种方法充分利用了 SLM 的优势,大大提高了移动设备上 GUI agent 的效率和性能。
**以用户为中心的适应性:****交互与个性化。**当前的 agent 通常依赖大量的人工干预来纠正错误或指导任务执行,从而破坏了用户的无缝体验。提高 agent 理解用户意图的能力并减少人工调整至关重要。
未来的研究应提高自然语言理解能力,结合语音命令和手势,并使 agent 能够从用户反馈中不断学习。个性化同样重要, agent 应快速适应新任务和用户的特定环境,而无需进行昂贵的再培训。将人工教学、零镜头学习和少镜头学习结合起来,可以帮助 agent 从最小的用户输入中进行泛化,使其更加灵活和普遍适用。
提升模型能力:接地(grounding)、推理及其他**。**准确地将语言指令与特定的用户界面元素相结合是一个主要障碍。虽然 LLM 擅长语言理解,但将指令映射到精确的用户界面交互需要改进的多模态基础。
未来的工作应整合先进的视觉模型、大规模注释和更有效的融合技术。agent 必须处理错综复杂的工作流程,解释模棱两可的指令,并随着环境的变化动态调整策略。要实现这些目标,可能需要采用新的架构、记忆机制和推理算法。
**评估基准标准化。**客观且可重复的基准对于比较模型性能至关重要。现有的基准通常针对狭窄的任务或有限的领域,使综合评估变得复杂。
涵盖不同任务、应用类型和交互模式的统一基准将促进公平的比较,并鼓励采用更通用、更强大的解决方案。这些基准应提供标准化的指标、场景和评估协议,使研究人员能够更清晰地识别优势、劣势和改进路径。
**确保可靠性和安全性。**由于 agent 可以访问敏感数据并执行关键任务,因此可靠性和安全性至关重要。当前的系统可能会受到恶意攻击、数据泄露和意外操作的影响,LLM agent 也容易受到后门攻击。
业内需要强大的安全协议、错误处理技术和隐私保护方法来保护用户信息和维护用(yòng)户信任。采用数据本(běn)地(de)化(huà)、加(jiā)密(mì)通(tōng)信(xìn)和(hé)匿(nì)名化(huà)等(děng)技(jì)术(shù)可(kě)以(yǐ)在(zài)收(shōu)集数(shù)据(jù)的(de)同(tóng)时(shí)有(yǒu)效(xiào)保(bǎo)护(hù)用(yòng)户(hù)隐(yǐn)私(sī)。持(chí)续(xù)监(jiān)控(kòng)和(hé)验(yàn)证(zhèng)流(liú)程(chéng)可(kě)以(yǐ)实(shí)时(shí)检(jiǎn)测(cè)漏(lòu)洞(dòng)并(bìng)降(jiàng)低(dī)风(fēng)险(xiǎn)。确(què)保(bǎo) agent 的(de)行(xíng)为(wèi)具(jù)有(yǒu)可(kě)预(yù)测(cè)性(xìng)、尊(zūn)重(zhòng)用(yòng)户(hù)隐(yǐn)私(sī)并(bìng)在(zài)具(jù)有(yǒu)挑(tiāo)战(zhàn)性(xìng)的(de)条(tiáo)件(jiàn)下(xià)保(bǎo)持(chí)稳(wěn)定(dìng)的(de)性(xìng)能(néng),对(duì)于(yú)广(guǎng)泛(fàn)应(yīng)用(yòng)和(hé)长(zhǎng)期(qī)可(kě)持(chí)续(xù)发(fā)展(zhǎn)至(zhì)关重(zhòng)要(yào)。
研(yán)究(jiū)团(tuán)队(duì)表(biǎo)示(shì),要(yào)应(yīng)对(duì)上(shàng)述(shù)挑(tiāo)战(zhàn),业(yè)内(nèi)需(xū)要(yào)在(zài)数(shù)据(jù)收(shōu)集、模(mó)型(xíng)训(xun)练(liàn)策(cè)略(è)、硬(yìng)件(jiàn)优(yōu)化(huà)、以(yǐ)用(yòng)户(hù)为(wèi)中(zhōng)心(xīn)的(de)适(shì)应(yīng)性(xìng)、改(gǎi)进(jìn)基(jī)础(chǔ)和(hé)推(tuī)理(lǐ)、标(biāo)准(zhǔn)化(huà)基(jī)准(zhǔn)和(hé)强(qiáng)大(dà)的(de)安(ān)全措(cuò)施(shī)等(děng)方(fāng)面(miàn)共(gòng)同(tóng)努(nǔ)力(lì)。
他(tā)们(men)认(rèn)为(wèi),下(xià)一(yī)代(dài)由(yóu) LLM 驱(qū)动(dòng)的(de)手(shǒu)机(jī) GUI agent,将(jiāng)变(biàn)得(de)更(gèng)加(jiā)高(gāo)效(xiào)、可(kě)信(xìn)和(hé)有(yǒu)能(néng)力(lì),最(zuì)终(zhōng)在(zài)动(dòng)态(tài)移(yí)动(dòng)环(huán)境(jìng)中(zhōng)为(wèi)用(yòng)户(hù)提(tí)供(gōng)无(wú)缝(fèng)、个(gè)性(xìng)化(huà)和(hé)安(ān)全的(de)体(tǐ)验(yàn)。
此(cǐ)外(wài),更(gèng)广(guǎng)泛(fàn)的(de)人(rén)工(gōng)智(zhì)能(néng)范(fàn)式(shì)(如(rú)具(jù)身(shēn) AI 和(hé) AGI)将(jiāng)会(huì)融(róng)合(hé)到(dào)手(shǒu)机(jī)自(zì)动(dòng)化(huà)中(zhōng),从(cóng)而(ér)使(shǐ) agent 能(néng)够(gòu)在(zài)最少的人工监督下处理日益复杂的任务。
作者:与可